Árboles de Regresión usando Python
En minería de datos, machine learning y/o ciencia de datos, en lo que se refiere al análisis con árboles, existen dos enfoques principales: los árboles de decisión y los árboles de regresión.
En ambos casos los árboles constituyen métodos predictivos de segmentación, conocidos como árboles de clasificación. Son particiones secuenciales del conjunto de datos realizadas para maximizar las diferencias de la variable dependiente dado que se realiza una división de los casos en grupos.
A través de diferentes índices y procedimientos estadísticos se determina la división más discriminante de entre los criterios seleccionados, aquella que permite diferenciar mejor a los distintos grupos del criterio base, con lo que se obtiene así, una primera segmentación. A partir de esa primera segmentación, se realizan nuevas segmentaciones de cada uno los segmentos resultantes y así sucesivamente hasta que el proceso finaliza con alguna norma estadística.
Supongamos ahora que deseamos conocer que pasajeros del Titanic tuvieron más probabilidades de sobrevivir a su hundimiento y qué características estuvieron asociadas a la supervivencia del naufragio. En este caso la variable de interés (GS) es el grado de supervivencia.
Podríamos entonces dividir a los pasajeros en grupos por edad, sexo, clase en la que viajaban y observar la proporción de supervivientes de cada grupo.
Un procedimiento basado en árboles, selecciona automáticamente los grupos homogéneos con la mayor diferencia en proporción de supervivientes entre ellos. En el primer caso, sexo (hombres y mujeres).
El siguiente paso consta en subdividir cada grupo de hombres y mujeres en función de otra características. Resultando que los hombres son divididos en adultos y niños, mientras que las mujeres se dividen en grupos basados en la clase en la que viajaban.
Cuando se termina el proceso de subdivisión, el resultado es un conjunto de reglas que pueden visualizarse fácilmente mediante un árbol.
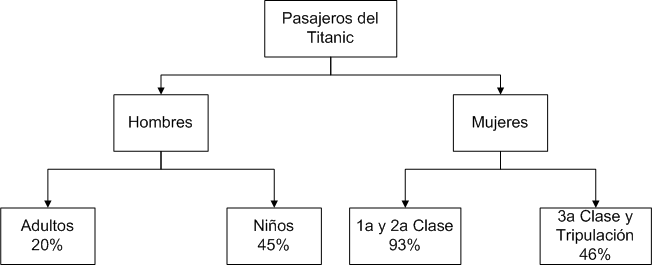
Con la representación de la figura anterior podemos observar, por ejemplo, que si un pasajero es hombre y es adulto, entonces tiene una probabilidad de sobrevivir del 20%.
La proporción de la supervivencia en cada una de las subdivisiones puede utilizarse con fines predictivos para vaticinar el grado de supervivencia de los miembros de ese grupo.
Utilizando diferentes predictores (variables independientes) en cada nivel del proceso de división representa una forma sencilla y elegante de manejar iteraciones.
El procedimiento crea un modelo de clasificación basado en árboles, y clasifica casos en grupos o pronostica valores de una variable dependiente basada en los valores de las variables independientes.
- Segmentación. Identifica individuos que pueden ser miembros de un grupo específico.
- Estratificación. Asigna los casos a una categoría de entre varias, por ejemplo grupos de alto riesgo, bajo riesgo o riesgo intermedio.
- Predicción. Crea reglas y las utiliza para predecir eventos futuros, como verosimilitud de que una persona cause mora en un crédito, o el valor de reventa de un vehículo o de un inmueble
Un análisis de datos basado en árboles permite identificar grupos homogéneos con alto o bajo riesgo y facilita la construcción de reglas para realizar pronósticos sobre casos individuales.
Para los árboles tanto las variables dependientes e independientes pueden ser nominales, ordinales y de escala.
- Son nominales cuando sus valores presentan categorías que no obedecen a un orden intrínseco. Por ejemplo, el área donde trabaja un empleado
- Son ordinales cuando sus valores presentan categorías con algún orden intrínseco. Por ejemplo, los niveles de satisfacción de un servicio.
- Son de escala cuando sus valores representan categorías ordenadas con una métrica con significado, por que aquí son adecuadas las comparaciones de distancia entre valores. Por ejemplo, la edad en años, los ingresos en moneda, etc.
Tipos de árboles
Los tres tipos de árboles más utilizados hoy en día son: árboles CHAID, árboles CART y árboles QUEST
- Árboles CHAID (Chi-square Automatic Interaction Detector). Es la conclusión de una serie de métodos basados en el detector automático de interacciones (AID) de Morgan y Sonquist. Es un método exploratorio útil para identificar variables importantes y sus interacciones enfocadas a la segmentación y a los análisis descriptivos.
- Árboles CART (Classification and Regression Tree). Es una alternativa al CHAID exhaustivo para árboles de clasificación con variables dependientes categóricas. Por lo que se utiliza para clasificación con variables dependiente cualitativa y para regresión con variable dependiente cuantitativa, generando árboles binarios.
- Árboles QUEST (Quick, Unbiased, Efficient, Statistica Tree). Consiste en un algoritmo de clasificación arborescente creado especialmente para solventar dos de los principales problemas que presentan los métodos CART y CHAID exhaustivo a la hora de dividir un grupo de sujetos en función de una variable independiente.
En este artículo nos enfocaremos en los árboles CART para regresión y en el siguiente lo haremos para clasificación.
Algoritmo para los Árboles CART de regresión
Supongamos que tenemos un conjunto de datos con dos variables dependientes X1 y X2 y Y siendo la variable dependiente a predecir.
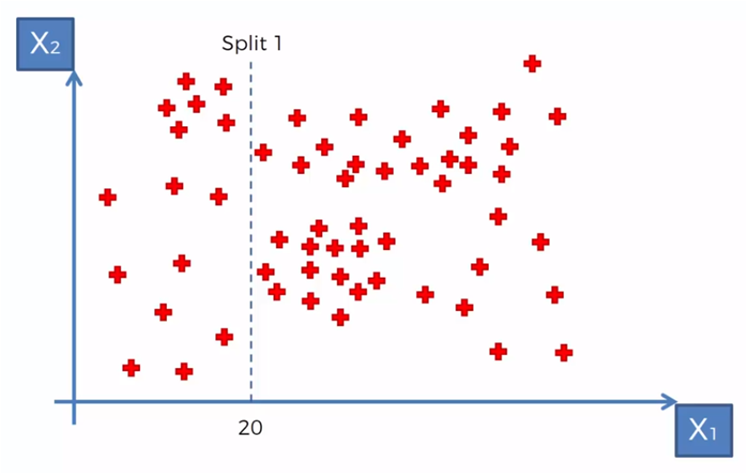
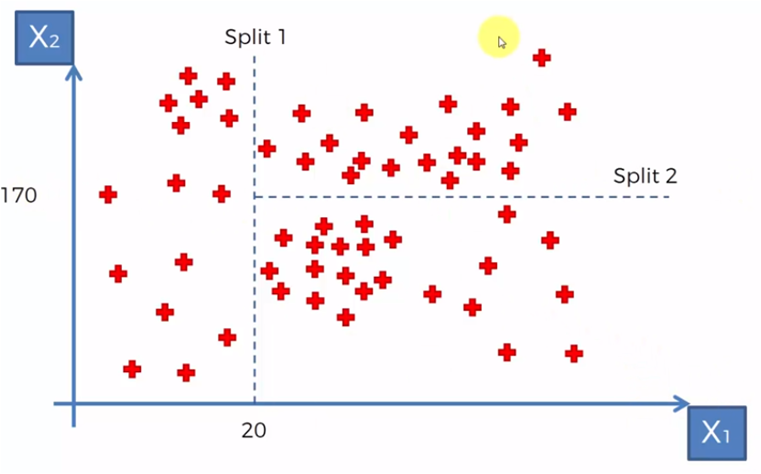
De acuerdo con algunos criterios establecidos podríamos empezar a segmentar los datos en relación a ciertos valores para X1 y X2. Por ejemplo si necesitamos crear grupos con datos donde X1 es menor a 20, tendríamos un grupo para X1 < 20 y un grupo para X1 >= 20, entonces para el algoritmo creamos una división en X1 = 20
Después, para los datos donde X1 > 20 requerimos crear un grupo de valores con X2 > 170 y X2 <= 170, por lo que marcamos otra división como en la gráfica siguiente.
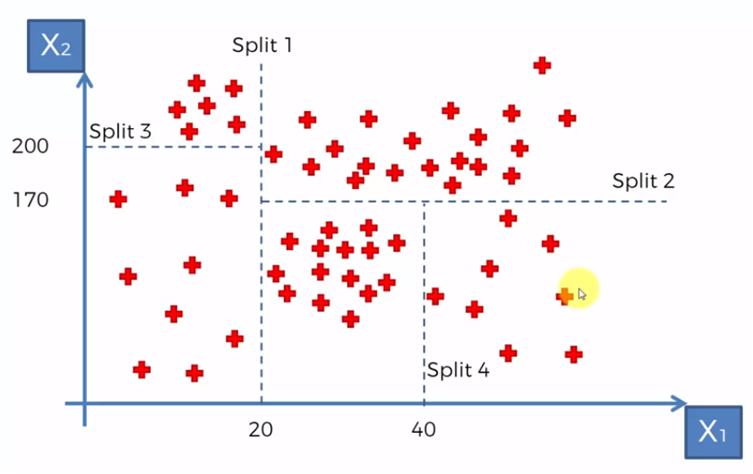
y luego de esto, creamos dos divisiones más, una para los datos donde X1 < 20, dividimos en dos grupos, los que tienen valores para X2 menor y mayor a 200. La división 4 para los datos donde X2 > 20 y X1 < 170, requerimos los que son mayores a 40 en X1
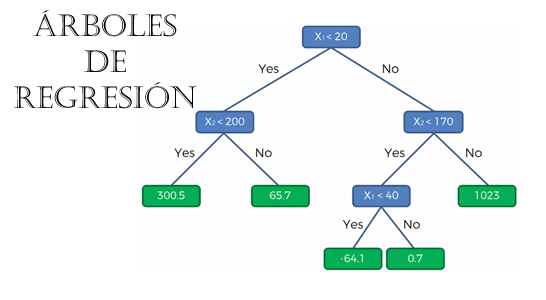
Conforme se van creando los segmentos, se va formando una estructura binaria, tipo árbol de la siguiente manera, donde representamos los grupos en base a las líneas de división mostradas en las gráficas anteriores.
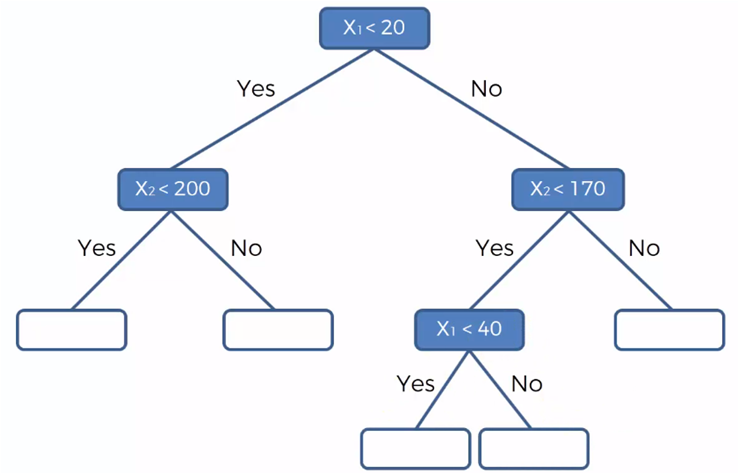
Los nodos azules representan las cuatro divisiones que se realizaron en las gráficas del conjuntos de datos y los nodos blancos, los datos que pertenecen a cada grupo. Si en cada uno de estos grupos el valor de la variable dependiente es el mismo dentro del mismo grupo y distinto entre grupos. Podemos ahora predecir el valor de Y (variable dependiente) para datos desconocidos o adicionales con valores para X1 y X2 que caen en un grupo específico.
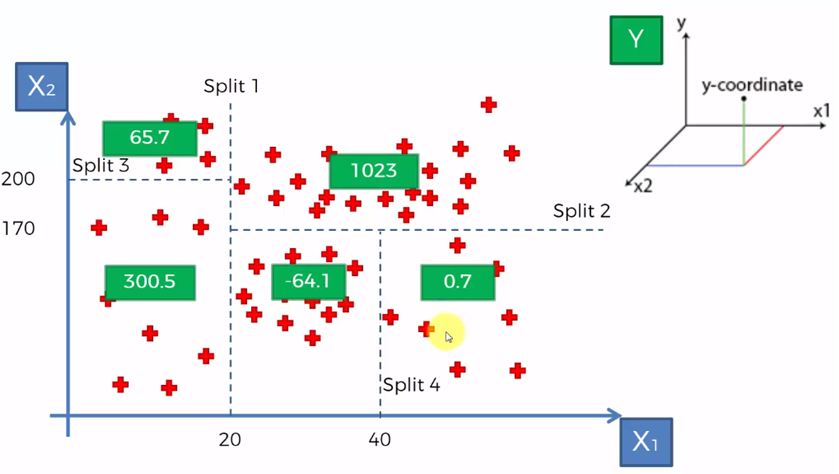
Los recuadros verdes representan el valor de Y (la variable dependiente) y ahora representado en el gráfico del árbol, lo demos de la siguiente manera:
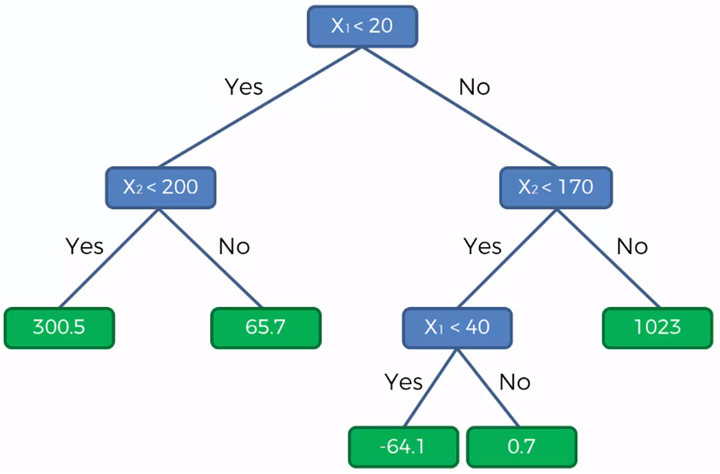
Con este diagrama podemos determinar que, por ejemplo, el valor de Y para un punto dado por (28, 115) donde X1 = 28 y X2 = 115, entonces Y será igual a -64.10
Árboles de Regresión con Python
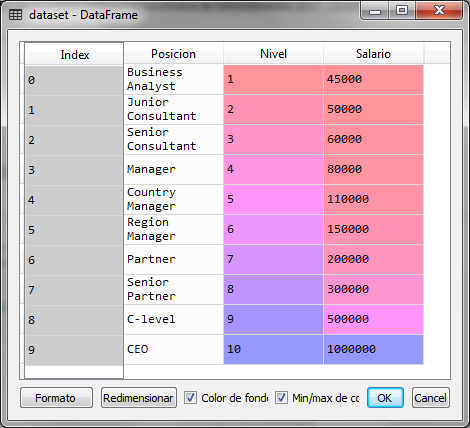
Para el ejemplo con python, supongamos que tenemos el siguiente conjunto de datos que representa el salario de un empleado de acuerdo al nivel y puesto en el que se encuentra en la organización
| Posición | Nivel | Salario |
| Business Analyst | 1 | 45,000 |
| Junior Consultant | 2 | 50,000 |
| Senior Consultant | 3 | 60,000 |
| Manager | 4 | 80,000 |
| Country Manager | 5 | 110,000 |
| Region Manager | 6 | 150,000 |
| Partner | 7 | 200,000 |
| Senior Partner | 8 | 300,000 |
| C-level | 9 | 500,000 |
| CEO | 10 | 1,000,000 |
Cargamos las librerías y el archivo de datos que contiene la tabla anterior, donde utilizaremos el nivel como la variable independiente y el salario como la variable dependiente.
#Árboles de Regresión
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Salario_por_Posicion.csv')
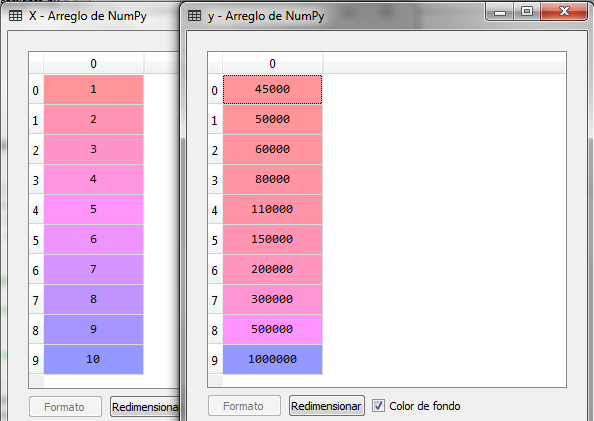
X = dataset.iloc[:, 1:2].values
y = dataset.iloc[:, 2].values
Una vez ejecutado el fragmento de código anterior obtenemos el dataset y las variables X y Y
El siguiente paso es importar la clase DecisionTreeRegressor del paquete tree de la librería sklearn para crear un objeto regressor y ajustar los datos X y Y y posteriormente hacer la predicción con un valor de Nivel 6.5, es decir un puesto en la organización que tenga el nivel 6.5
#Regresion Lineal Simple
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('Salario_por_Posicion.csv')
X = dataset.iloc[:, 1:2].values
y = dataset.iloc[:, 2].values
# Ajuste del arbol de decision al dataset
from sklearn.tree import DecisionTreeRegressor
regressor = DecisionTreeRegressor(random_state = 0)
regressor.fit(X, y)
# Prediccion del salario para el nivel 6.5
y_pred = regressor.predict(6.5)
Después de ejecutar los últimos fragmentos del código, y_pred que es la variable donde guarda el resultado de predecir a que grupo pertenece el valor de 6.5 para el nivel salarial tenemos los siguiente:
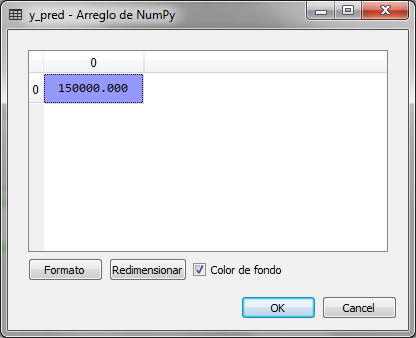
Observamos que el resultado es 150,000, el cual corresponde al salario del nivel 6, es decir el nodo del nivel 6 corresponde para valores de X desde 5.6 a 6.5, para observarlo de esa forma creamos la siguiente gráfica:
# Visualizacion de los resultados del arbol de decision
X_grid = np.arange(min(X), max(X), 0.01)
X_grid = X_grid.reshape((len(X_grid), 1))
plt.scatter(X, y, color = 'red')
plt.plot(X_grid, regressor.predict(X_grid), color = 'blue')
plt.title('Decision Tree Regression')
plt.xlabel('Nivel Posicion')
plt.ylabel('Salario')
plt.show()
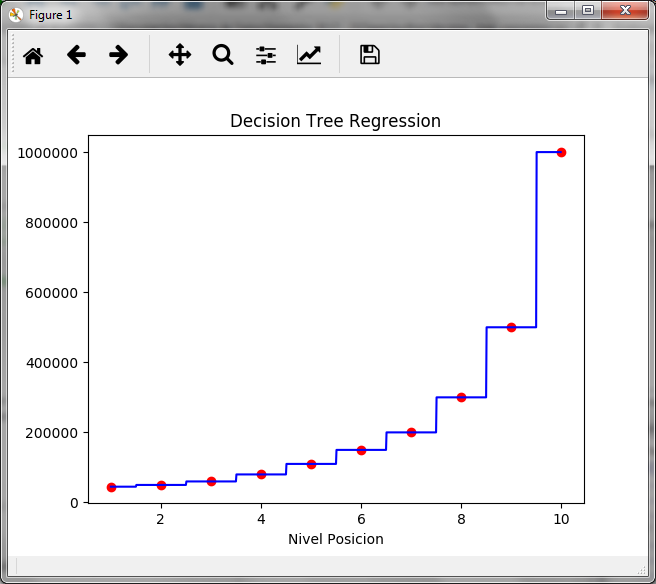
Como se observa en la gráfica escalonada, el valor de 150,000 para el salario se mantiene desde el nivel 5.6 al nivel 6.5. Un nivel 6.6 ya nos daría un salario de 200,000 que corresponde al nivel 7.
Los árboles de regresión permiten predecir un valor para la variable dependiente que pertenezca a un grupo creado por el árbol.
Recursos y comentarios adicionales
Ejecutar los modelos de machine learning en la nube puede ser una ventaja dependiendo de la cantidad de datos que tenemos dado que podríamos requerir de mayor poder de procesamiento para el entrenamiento del modelo.
En este sentido, conocer las ventajas de los servicios en la nube se convierte en una necesidad importante, por lo que en el siguiente enlace podrías aprender, de manera muy económica, AWS (Amazon Web Service) con la certificación ya sea de asociado o profesional: AWS Professional Certification
Si por el contrario te interesa Azure, aquí puedes ver de forma gratuita un webinar que te presenta todas las ventajas y como iniciar con Azure
Buenos información, gracias por compartir conocimiento.
Por favor será posible compartir la ppt y la data de todos los temas tratados.
Gracias
Buenos información, gracias por compartir conocimiento.
Por favor será posible compartir la ppt y la data de todos los temas tratados.
Gracias
Hola, Gracias
Te paso el link para descargarlo
https://drive.google.com/drive/folders/1Jdg2ttdM8pvSdC2ndd5tS5rPI37uTC_t?usp=sharing
Gracias, te paso el link para descargarlos
https://drive.google.com/drive/folders/1Jdg2ttdM8pvSdC2ndd5tS5rPI37uTC_t?usp=sharing